Tu Propio "Claude Code" Local en Mac: OpenCode + MLX Optimizado para Apple Silicon
rea tu propio Claude Code 100% local en Mac. Guía paso a paso para configurar OpenCode con MLX y exprimir tu Apple Silicon sin pagar por suscripciones.
Tu Propio "Claude Code" Local en Mac: OpenCode + MLX Optimizado para Apple Silicon
¿Quieres un agente de código que corra a máxima velocidad en tu Mac, sin pagar suscripciones ni mandar tu código a la nube? En esta guía vas a montar OpenCode con MLX — el framework de machine learning de Apple — para exprimir cada gota de rendimiento de tu chip M. Al terminar tendrás un agente que lee tu repo, edita archivos y ejecuta comandos, corriendo 100% local y aprovechando la memoria unificada de Apple Silicon.
Y para lo que el modelo local no alcance, te muestro cómo añadir APIs baratas como respaldo, todo desde la misma terminal.
Lo que necesitas
- Mac con Apple Silicon (M1, M2, M3 o M4)
- 16GB de memoria unificada como mínimo
- macOS 14 o superior
- Homebrew instalado (brew.sh)
- Python 3.9+ (
python3 --version) - ~5GB de disco libre por modelo
¿Por qué MLX y no Ollama? Ollama funciona bien, pero su backend MLX hoy exige 32GB+ de RAM. Usar MLX-LM directamente no tiene esa restricción y rinde 10–20% más que la ruta tradicional (llama.cpp/GGUF) porque habla directo con Metal y la memoria unificada. En Apple Silicon, es la vía óptima.
1. ¿Qué es esta arquitectura?
OpenCode es un agente de código para tu terminal, parecido a Claude Code, pero tú eliges qué modelo lo impulsa. Lo conectaremos a MLX-LM, la pila que Apple presentó para correr IA agéntica local en el Mac.
Son cuatro capas, de abajo hacia arriba:
┌─────────────────────────────────┐
│ OpenCode (el agente / tu TUI) │ ← tu "Claude Code" local
├─────────────────────────────────┤
│ MLX-LM Server (API OpenAI) │ ← sirve el modelo en localhost:8080
├─────────────────────────────────┤
│ MLX-LM (carga y cuantiza) │
├─────────────────────────────────┤
│ MLX (Metal + memoria unificada)│ ← exprime tu chip M
└─────────────────────────────────┘
La gracia: MLX-LM Server expone una API compatible con OpenAI, así que OpenCode se conecta como si fuera cualquier proveedor de la nube — pero todo ocurre en tu máquina.
2. Instalar MLX-LM
Lo más limpio es con pipx, que instala la herramienta en su propio entorno aislado y la deja disponible globalmente:
brew install pipx
pipx ensurepath
pipx install mlx-lm
Abre una terminal nueva (para que el PATH se actualice) y verifica:
mlx_lm.generate --help
¿Por qué pipx y no pip? Con
pip installdirecto, macOS suele lanzar el error "externally-managed-environment".pipxlo evita y mantiene tu sistema limpio: actualizas conpipx upgrade mlx-lmy desinstalas sin dejar rastros.
3. Elegir y servir el modelo
3.1 Los mejores modelos MLX para 16GB (2026)
Después de probar varios en un M4, estos son los que valen la pena:
| Modelo | Tamaño (4-bit) | Mejor para |
|---|---|---|
| Qwen3-8B ⭐ | ~4.6GB | Driver principal: razonamiento + uso de herramientas, contexto de 256K |
| Qwen2.5-Coder-7B | ~4.3GB | Generación rápida de código y boilerplate |
| GLM-4-9B | ~5GB | Alternativa fuerte en tool calling |
| Phi-4 | ~8GB | Explicar conceptos paso a paso (contexto limitado a 16K) |
⚠️ Lo que NO cabe en 16GB: modelos como Kimi K2 (1 billón de parámetros, necesita 500GB+) o Qwen3-Coder-Next (necesita 45GB+). Los verás recomendados en foros, pero son para Macs de 64GB+ o Mac Studios. Ignóralos.
3.2 Arrancar el servidor
El modelo recomendado para empezar es Qwen3-8B, porque razona y usa herramientas mejor que un modelo "Coder" puro:
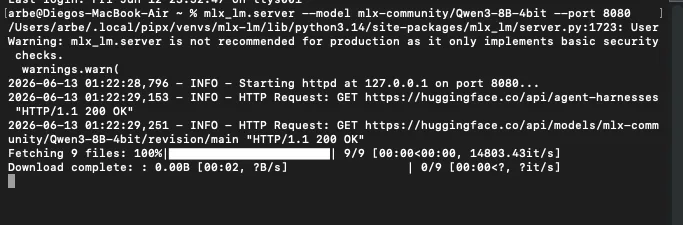
mlx_lm.server --model mlx-community/Qwen3-8B-4bit --port 8080
La primera vez descarga el modelo de Hugging Face automáticamente (~4.6GB). Después se queda "quieto" esperando peticiones — eso significa que está listo, no colgado.
Aqui ya esta corriendo el modelo, solo abres opencode en otra terminal.
como recomendación puedes hacer un script para que cada vez que se te abra opencode el modelo local tambien se active.
 > Tip: crea un alias para no escribir el comando completo cada vez:
> Tip: crea un alias para no escribir el comando completo cada vez:
echo 'alias mlx-server="mlx_lm.server --model mlx-community/Qwen3-8B-4bit --port 8080"' >> ~/.zshrc source ~/.zshrcA partir de ahí, solo escribes
mlx-server.
3.3 Verificar que funciona
En otra terminal (sin cerrar la del servidor):
curl http://localhost:8080/v1/models
Si responde un JSON con el nombre del modelo, el motor está vivo.
4. Instalar y Conectar OpenCode
4.1 Instalar
brew install sst/tap/opencode
opencode --version
Idealmente versión 1.14 o superior.
4.2 Configurar
Crea ~/.config/opencode/opencode.json:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"mlx": {
"npm": "@ai-sdk/openai-compatible",
"name": "MLX local",
"options": {
"baseURL": "http://localhost:8080/v1"
},
"models": {
"mlx-community/Qwen3-8B-4bit": {
"name": "Qwen3 8B (MLX)",
"limit": { "context": 32768, "output": 8192 }
}
}
}
}
}
⚠️ El error más común: la
baseURLdebe terminar en/v1. Sin eso, OpenCode no conecta y verás "0 tokens" sin moverse.
Verifica que el JSON sea válido:
cat ~/.config/opencode/opencode.json | python3 -m json.tool
Si te imprime el JSON formateado sin errores, está bien.
5. La Rutina Diaria (Importante)
OpenCode no levanta el modelo por ti. Siempre, en este orden:
Terminal 1 (déjala abierta mientras trabajas):
mlx-server
Terminal 2 (aquí trabajas):
cd mi-proyecto
opencode
 Si cierras la Terminal 1, OpenCode deja de poder hablar con el modelo aunque la interfaz siga abierta — por eso parece que "cuelga" sin avisar. Ese servidor es tu motor encendido.
Si cierras la Terminal 1, OpenCode deja de poder hablar con el modelo aunque la interfaz siga abierta — por eso parece que "cuelga" sin avisar. Ese servidor es tu motor encendido.
💡 Tip: abre la segunda terminal rápido con Cmd + T (nueva pestaña) y alterna entre pestañas con Cmd + 1 y Cmd + 2.
6. Usar OpenCode Como un Pro
6.1 Inicializa el proyecto
opencode
/init analiza tu código y genera AGENTS.md: un archivo con las convenciones, comandos de build y estructura de tu proyecto. Es el equivalente al CLAUDE.md de Claude Code, y reduce mucho los errores del agente. Comételo a git.
6.2 Plan vs Build
Pulsa Tab para alternar:
Plan: analiza y propone, sin tocar archivos.
Build: ejecuta los cambios.
 Para tareas no triviales, empieza en Plan, revisa, y pasa a Build.
Para tareas no triviales, empieza en Plan, revisa, y pasa a Build.
6.3 Comandos esenciales
| Comando | Qué hace |
|---|---|
/models |
Cambia de modelo |
/init |
Genera o actualiza AGENTS.md |
/compact |
Resume la conversación para liberar contexto |
/undo |
Revierte el último cambio del agente |
!comando |
Ejecuta un comando shell directo (ej: !flutter test) |
@archivo |
Adjunta un archivo específico al contexto |
6.4 El truco para no esperar de más
Un modelo de 8B local es más lento explorando que uno de la nube. En vez de pedirle "revisa la carpeta X" (lo que dispara un bucle lento de lecturas), explora tú con ! y luego dale una instrucción acotada:
!ls lib/services/
explícame @lib/services/database_helper.dart
El @ adjunta el archivo directo al contexto, sin que el modelo tenga que "decidir" leerlo. Mucho más rápido.
7. Respaldo en la Nube: APIs Baratas
Sé honesto contigo: un 8B local tiene techo. Para refactors grandes, bugs difíciles o aprender conceptos a fondo, una API de la nube te da calidad muy superior por centavos. Añádelas como segundo proveedor.
| Proveedor | Modelo | Gancho |
|---|---|---|
| DeepSeek | V4 Flash / Pro | El más barato; ~$0.27/M tokens |
| Alibaba (Qwen) | Qwen3.6 Plus | 70M tokens gratis al registrarte (90 días) |
Se conectan igual que el local (compatibles con OpenAI). Agrega a tu opencode.json dentro de provider:
"deepseek": {
"npm": "@ai-sdk/openai-compatible",
"name": "DeepSeek",
"options": {
"baseURL": "https://api.deepseek.com",
"apiKey": "{env:DEEPSEEK_API_KEY}"
},
"models": {
"deepseek-v4-flash": { "name": "DeepSeek V4 Flash" },
"deepseek-v4-pro": { "name": "DeepSeek V4 Pro" }
}
}
Guarda la key como variable de entorno (nunca en el JSON):
echo 'export DEEPSEEK_API_KEY="sk-tu-key-aqui"' >> ~/.zshrc
source ~/.zshrc
Seguridad: si expones tu key por error (captura, commit, chat), regenérala de inmediato desde el dashboard del proveedor — una key filtrada puede generar cargos.
¿Cuánto gasta? Para un desarrollador individual, entre $5 y $30 al mes. La clave del costo es el contexto que se reenvía en cada turno, así que usa /compact seguido y acota tus peticiones.
Mini test
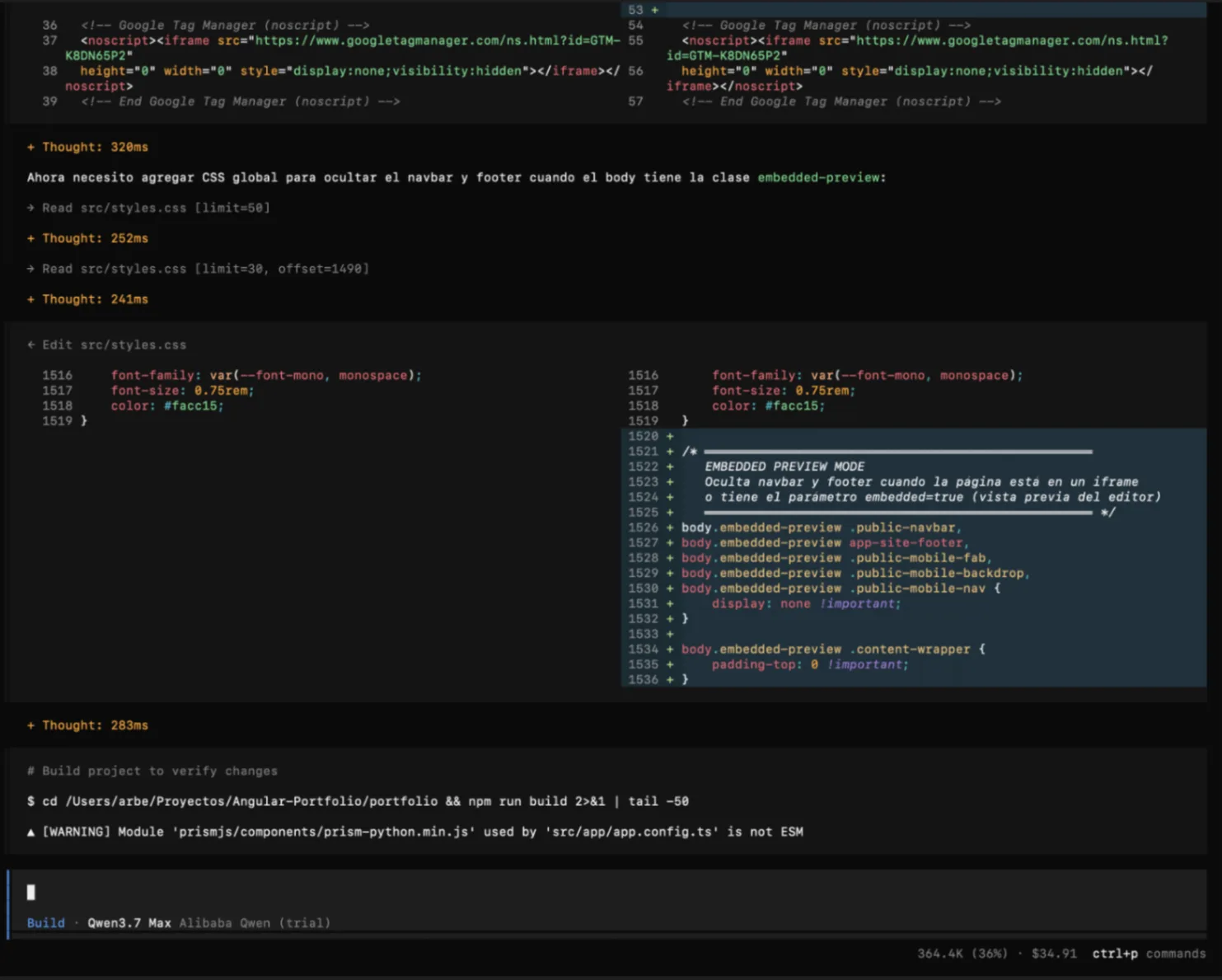 ---
---
8. El Setup Híbrido Recomendado
| Tarea | Qué usar | Por qué |
|---|---|---|
| Código sensible / sin internet | MLX local (Qwen3-8B) | Privacidad y cero costo |
| Boilerplate, snippets rápidos | MLX local (Qwen2.5-Coder) | Rápido, no necesita "pensar" |
| Refactor grande, bug difícil | API (DeepSeek Pro) | Razonamiento superior |
| Aprender conceptos a fondo | API (Alibaba / DeepSeek) | Explicaciones más confiables |
Cambias entre todos con /models en segundos. Trabajas gratis en local por defecto, y subes a la nube solo cuando la tarea lo amerita.
9. Troubleshooting
OpenCode muestra "0 tokens" y no responde
El servidor MLX no está corriendo o la baseURL no termina en /v1. Verifica con curl http://localhost:8080/v1/models.
"Connection refused"
Olvidaste arrancar mlx-server antes de abrir OpenCode. Levántalo primero.
El agente responde pero solo sugiere comandos, no los ejecuta
El modelo es débil en tool calling. Usa Qwen3-8B o GLM-4, no un modelo base.
La Mac se vuelve lentísima, el ventilador a tope
Falta de RAM (swap). Baja el limit.context de 32768 a 16384 en el JSON y cierra apps pesadas. Revisa la presión de memoria en Monitor de Actividad.
La primera respuesta tarda mucho
Normal: la primera petición tras arrancar el servidor incluye el tiempo de carga del modelo en memoria (10–30s extra). Las siguientes son más rápidas.
10. Checklist de Instalación
- [ ] Homebrew y Python 3.9+ instalados
- [ ]
pipx install mlx-lmejecutado y verificado - [ ] Modelo servido con
mlx_lm.server(espera a que cargue) - [ ]
curl http://localhost:8080/v1/modelsresponde - [ ] OpenCode instalado (
opencode --version) - [ ]
opencode.jsoncreado conbaseURLterminando en/v1 - [ ] JSON validado con
python3 -m json.tool - [ ] Alias
mlx-servercreado - [ ]
/initejecutado en tu proyecto - [ ] (Opcional) API de respaldo conectada con key en variable de entorno
Conclusión
Montaste un agente de código que corre a máxima velocidad en tu Mac, aprovechando MLX y la memoria unificada de Apple Silicon — gratis, privado y sin depender de internet. Y le diste un respaldo en la nube para cuando la tarea pida más músculo, todo desde la misma terminal.
es una buena alternativa para poder seguir codeando y revisando sintaxys si te has quedado sin tokens de claude code o como experimento, es la configuración que hice y funciona bien, no excelente por los limites de mi ram pero es algo bastante interesante de probar.
¿Qué sigue? Tres mejoras para llevarlo más lejos:
- Crear "skills" (archivos Markdown con tus convenciones) y referenciarlas desde
AGENTS.mdpara que el agente genere código con tu estilo. - Definir agentes especializados que deleguen tareas pesadas a la API automáticamente.
- Probar el alias con un script que verifique si el servidor ya está corriendo antes de levantarlo.
Guarda tu opencode.json en un gist o repo para replicar el setup en otra Mac en segundos. Si montaste el tuyo, cuéntame en los comentarios qué modelo MLX te dio mejor resultado.
Comentarios (0)